Introduction to Apache Kafka
The Next Gen Event Streaming System
James Ward | @_JamesWard
Developer @ Salesforce.com
Data Integration Today

Integration Complexity
- No System of Record
- Synchronization is hard
- Scaling ETL is hard
- Processing is error-prone
Events not Tables
Streams as Ledgers
First-class Partitioning
Why not message systems?
- Ordering?
- Horizontal Scaling?
- Push?

Kafka = Event Ledger - Distributed & Redundant
A Distributed Commit Log
Linear Clustering Performance
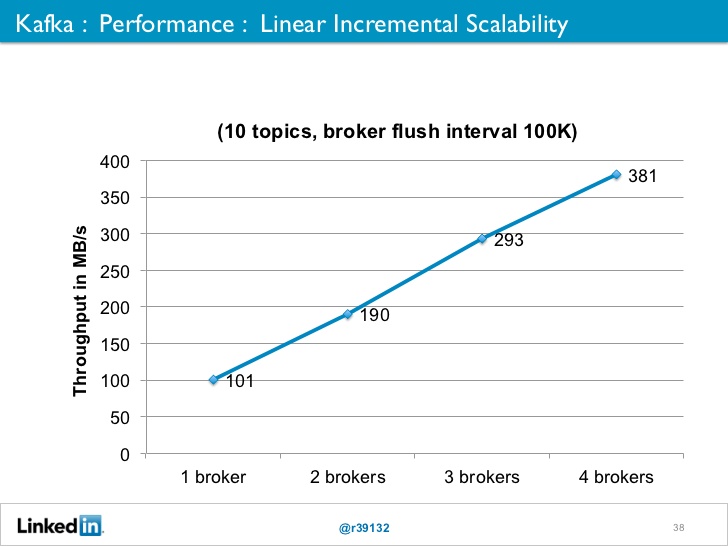
Near network speeds
Kafka Fundamentals
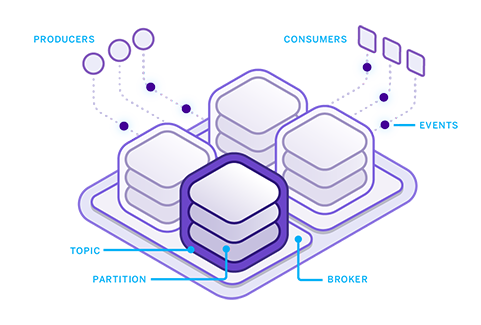
- Messaging System Semantics
- Clustering is Core
- Durability & Ordering Guarantees
Use Cases
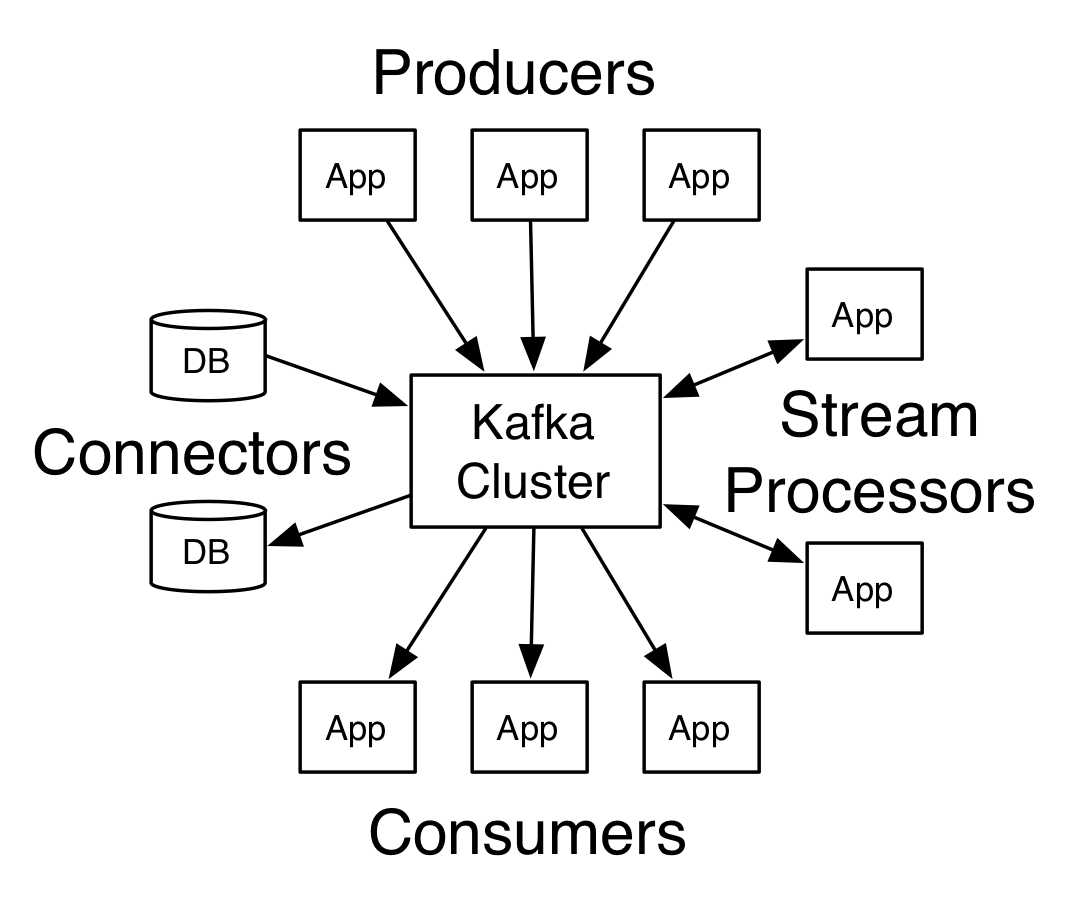
- Modern ETL / CDC
- Data Pipelines
- Big Data Ingest
Demo!

Records
- Key, Value, Timestamp
- Immutable
- Append Only
- Persisted
AKA: A Log
Producers & Consumers
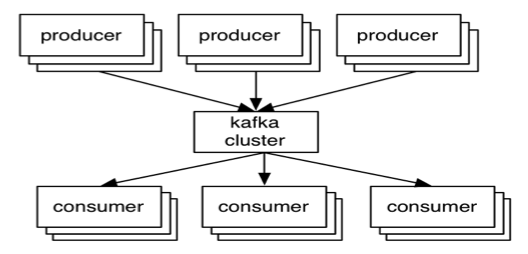
- Broker = Node in the cluster
- Producer writes records to a broker
- Consumer reads records from a broker
- Leader / Follower for cluster distribution
Topics & Partitions
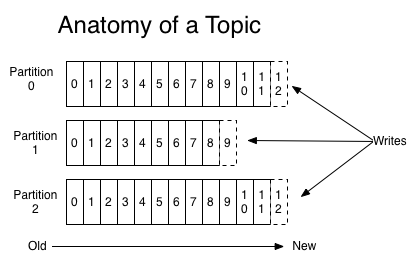
- Topic = Logical name with 1 or more partitions
- Partitions are replicated
- Ordering is guaranteed for a partition
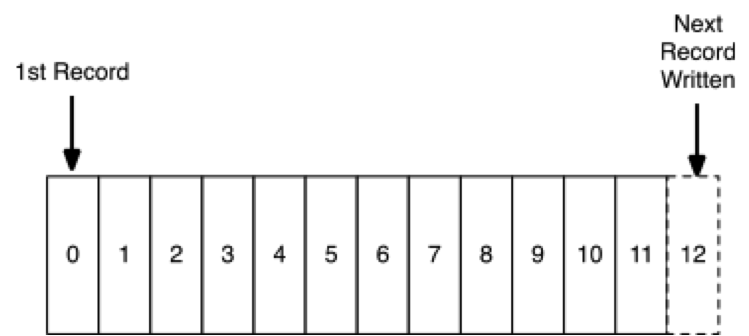
Offsets
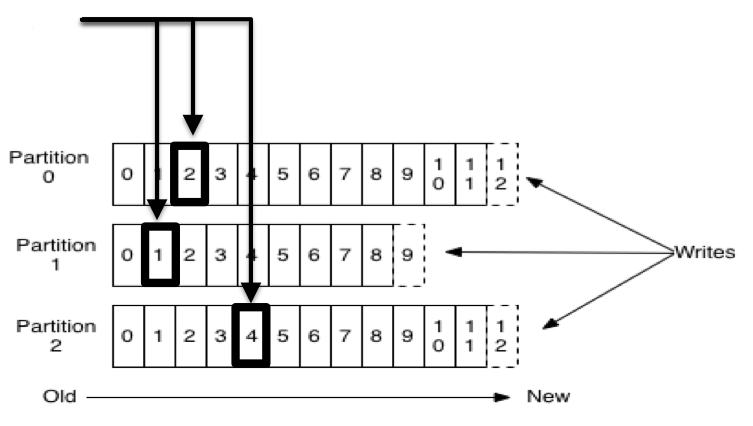
- Unique sequential ID (per partition)
- Consumers track offsets
- Benefits: Replay, Different Speed Consumers, etc
Producer Partitioning
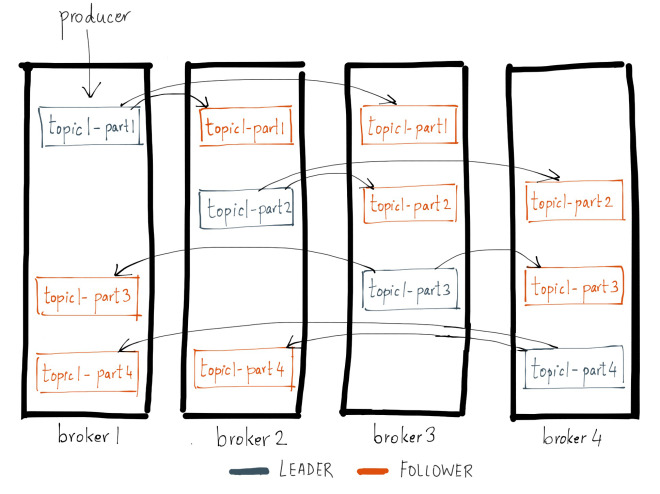
- Writes are to the leader of a partition
- Partitioning can be done manually or based on a key
- Replication Factor is Topic-based
- Auto-Rebalancing
Consumer Groups
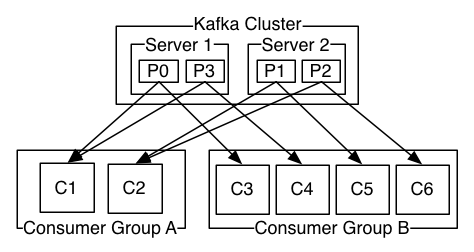
- Logical name for 1 or more consumers
- Message consumption is load balanced across all consumers in a group
Delivery Guarantees
Producer
- Async (No Guarantee)
- Committed to Leader
- Committed to Leader & Quorum
Consumer
- At-least-once (Default)
- At-most-once
- Effectively-once
- Exactly Once (Maybe)
Cool Features
- Log Compaction
- Disk not Heap
- Pagecache to Socket
- Balanced Partitions & Leaders
- Producer & Consumer Quotas
- Heroku Kafka
Clients
- JVM is official
- Most other platforms via the community
- Polling Based
Basic Connection
Producer
class Producer {
public void send(ProducerData<K,V> producerData);
}Consumer
class SimpleConsumer {
public ByteBufferMessageSet fetch(FetchRequest request);
public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);
}
interface ConsumerConnector {
public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap);
}Akka Streams
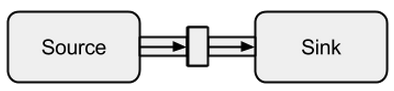
- Impl of Reactive Streams
- Source / Sink Stream Programming
- Back-pressure, etc
- Kafka Adapter:
https://github.com/akka/reactive-kafka
Akka Streams
val source = Source.repeat("hello, world")
val sink = Sink.foreach(println)
val flow = source to sink
flow.run()Code!
https://github.com/jamesward/kooberApache Flink
Real-time Data Analytics
- Bounded & Unbounded Data Sets
- Stream processing (map, fold, filter, etc)
- Distributed Core
- Fault Tolerant
- Flexible Windowing
Flink
Continuous Processing for Unbounded Datasets
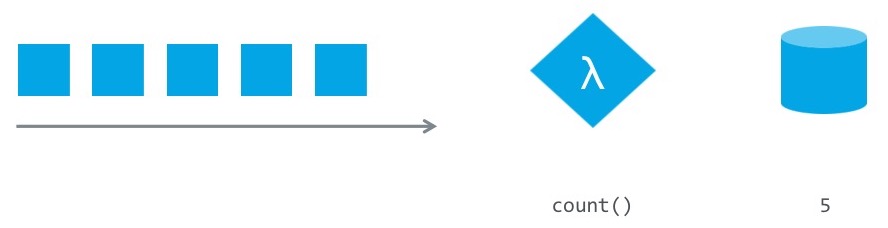
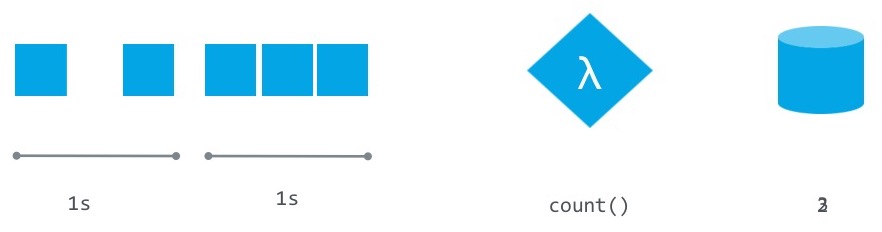
Flink - Windowing
Bounding with Time, Count, Session, or Data
Code!
https://github.com/jamesward/kooberHeroku Kafka
https://www.heroku.com/kafka
Questions?
Reach out: @_JamesWard